
RAG Document Chat
hey guys, this is my first ever post about my personal project. for your information, the time i'm writing this is around early June of 2026. i'm in the process of recruitments and some of them had take home assignments. this project is one of them. although i didn't pass the first screening, i was lucky enough to get their take home assignment. even though there's no point of doing this for the recruitment, i decided to do it to brush up my skills. also, since this assignment is from a top company in Taiwan, why not just do it?
to be honest, it's near graduation and i'm no longer so stressed about my thesis. that's why i have the time to explore and learn some other things. while i've learned RAG in 2025, this is a good experience to pick up my memory about it.
to put it simple, here's the task: build a website where you upload a document and chat with it. sounds simple until you read the fine print.
the LLM can only see 10K tokens at a time. you cannot use GPT or Gemini to parse the PDF, the LLM is strictly text-to-text. and the default test file? the LightRAG paper, which is… definitely longer than 10K tokens.
okay. challenge accepted. sort of..
first, the limitations (aka why we can't just ask nicely)
let me be honest about what we're working with:
1. the document is huge. the brain is small.
a research paper can easily be 30K–80K tokens. the assignment says assume 10K max context input and output combined. either way, you physically cannot dump the full PDF into one prompt and ask "summary this document."
2. the LLM is not allowed to read the PDF.
chunking, embedding, retrieval.. all of that happens outside the LLM. the model only ever sees the question plus a small slice of retrieved text. this is intentional. it keeps indexing fast, deterministic, and cheap.
3. naive search is not enough.
if you embed the question once, grab the top 5 chunks, and maybe pray, comparison questions like "compare X with Y" miss half the paper. ablation questions need chunks from the experiments section, not just the introduction. summaries need coverage across the whole document, not just the most semantically similar paragraph.
once i understood these walls, the plan became obvious: don't send the document. send the right pieces.
the plan: RAG, but actually good
RAG is the classic answer to "document too big for context window." but "classic" can mean "embed, search, generate, hope for the best." i didn't want hope. i wanted the three assignment test questions to actually work. or better, any questions should work on it (!!!)
here's what was sketched:
the key decisions:
chunk size 400 chars, overlap 100. small enough for precise retrieval, big enough to hold a thought. split on paragraph → sentence → word boundaries so we don't cut mid-sentence.
multi-query retrieval. the LLM rewrites the user's casual question into 2 formal academic search queries.
Reciprocal Rank Fusion (RRF). merge results from the original question + both rewritten queries. chunks that appear in multiple result sets float to the top.
cross-encoder reranking. bi-encoder search is fast but fuzzy.
bge-reranker-baserescores the top 15 candidates; we keep the best 8.neighbor expansion. for each hit, also pull chunk index ±1. fixes answers that got split across chunk boundaries.
intent-aware prompts. summary, comparison, technical, and Q&A each get different instructions and context budgets.
streaming via SSE. tokens appear in the UI as they're generated. waiting 30 seconds for a blank screen feels worse than watching text flow in.
🔨building it (the messy middle)
indexing: making the document searchable
first upload of the LightRAG paper creates 208 chunks. that's fine. the whole point is we never send all of them at once.
🔎query time: teaching the LLM to search smarter
before retrieval, one small LLM call in query_processor.py returns JSON:
intent can be summary, comparison, technical, or qa. if the LLM fails or returns garbage, we fall back to the raw question. no drama.
then vector_store.py does the heavy lifting: batch-embed all query variants, search ChromaDB, RRF-merge, rerank with max-score across all query phrasings, expand neighbors, return ordered chunks.
📝generation: staying inside the box
the llm service builds the prompt, trims context, and streams the answer. different intents get different max output tokens: summaries up to 2048, comparisons/technical 1536, Q&A 1024. those output tokens are reserved upfront when we trim context, so input + output never exceeds 10K.
honest aside: our first version approximated the budget with character counts (8K chars for Q&A, 12K for summaries). it worked, but the assignment literally asks "how do you handle tokens exceeding max context?" so we swapped to real token counting with the tokenizer.
how we handle file tokens exceeding the LLM max context size
this is the core constraint question, so let me be explicit: we never put the full document in the prompt.
the pipeline has three layers of protection:
layer 1 : chunking at index time
the PDF is split into ~400-character chunks with 100-character overlap during upload. a 50-page paper might become 200–400 chunks. each chunk is independently embedded and stored. the full document lives in vector db, not in the LLM context.
layer 2: retrieval instead of full-document injection
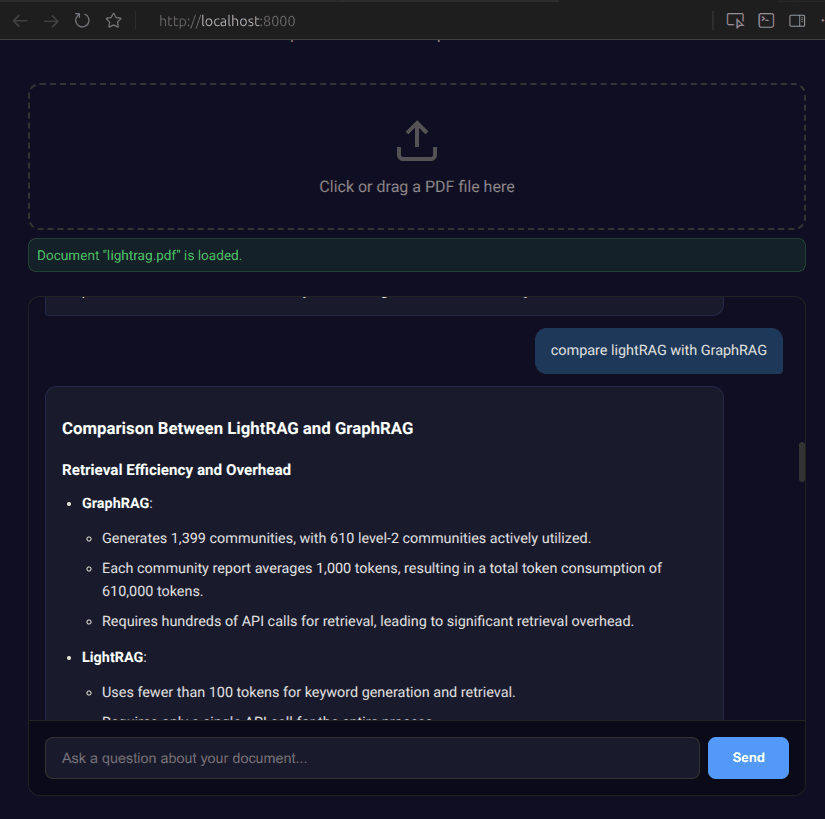
at query time, we retrieve only the most relevant chunks, default top 8 after reranking, plus neighbor expansion (so maybe 10–15 unique chunks in practice). for a comparison question, multi-query search + RRF + reranking ensures we pull chunks about LightRAG and GraphRAG, not just whichever name appeared more often in the embedding space.
layer 3: token budgeting before the LLM call
even retrieved chunks can add up. trim_chunks_to_token_budget() in token_budget.py counts tokens with the actual tokenizer — not a chars÷4 guess.
the rule: input_tokens + reserved_output_tokens ≤ 10,000
reserved output depends on intent (2048 for summary, 1536 for comparison/technical, 1024 for Q&A). that leaves an input budget of roughly 7,952–8,976 tokens for retrieved context + prompt template. we greedily add chunks, counting the full rendered chat template each time. if the next chunk would overflow, we stop — or binary-search truncate that chunk to fit.
real numbers from testing on the LightRAG paper:
question | input tokens | reserved output | total |
|---|---|---|---|
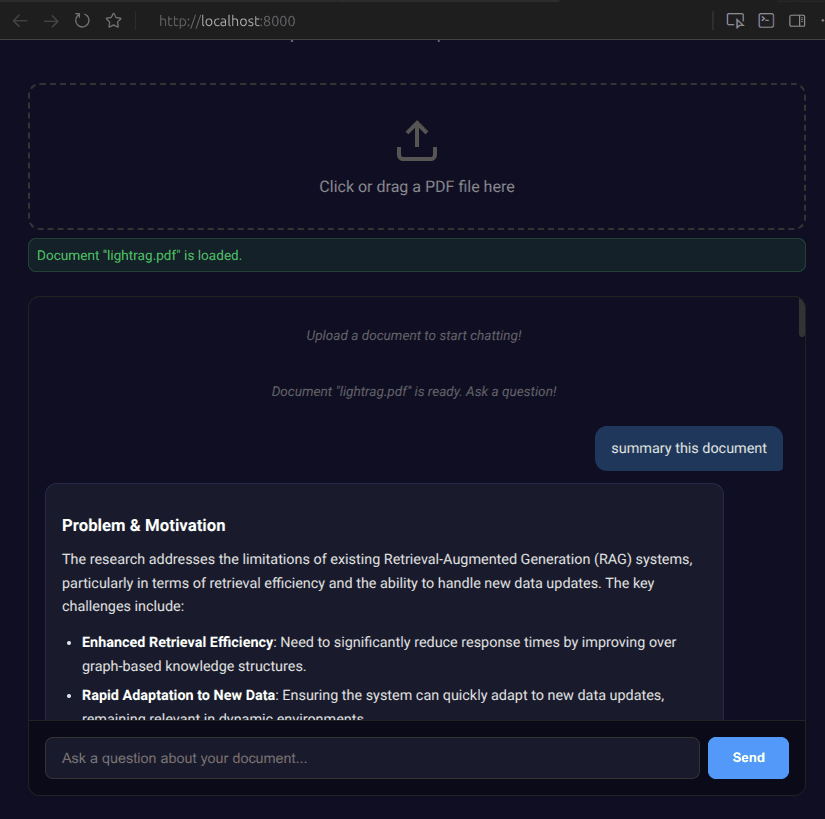
summary this document | 2,840 | 2,048 | 4,888 |
compare lightRAG with GraphRAG | 1,862 | 1,024 | 2,886 |
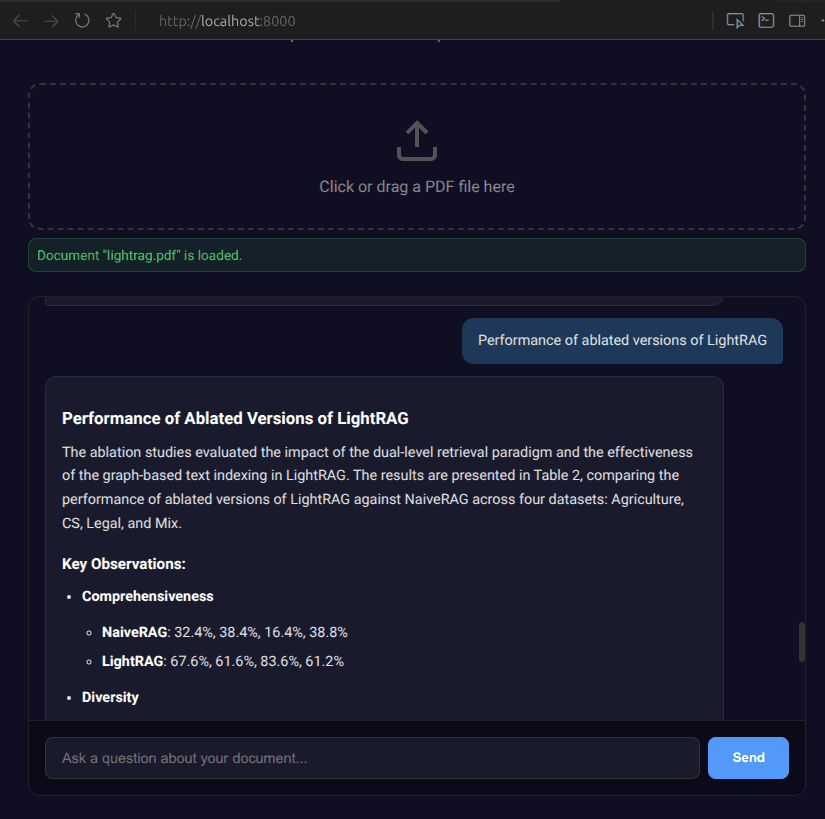
Performance of ablated versions of LightRAG | 1,792 | 1,536 | 3,328 |
all within budget. the LLM only ever sees a curated excerpt, not the file.
how we handle summaries
"summarize this document" is a different beast from "what dataset did they use?"😔
semantic search alone tends to return chunks similar to the word "summary" or the abstract.. which means you get a great intro paragraph and miss the experiments, ablations, and conclusion. that's not a summary. that's a vibes check.
so when intent = summary, we do hybrid retrieval:
1. diverse sampling across the full document
picks 12 chunks spaced across the entire chunk index range — beginning, middle, end, everything in between. this guarantees document-wide coverage even if no single chunk screams "i am about experiments."
2. semantic search on top
we still run the normal multi-query retrieval pipeline and merge its top hits.
3. merge and deduplicate
diverse samples + semantic results → dedupe → rerank → neighbor expand. you get breadth and relevance.
4. structured summary prompt
instead of a generic "summarize this," the LLM gets a template asking for specific sections:
Problem & Motivation
Proposed Approach
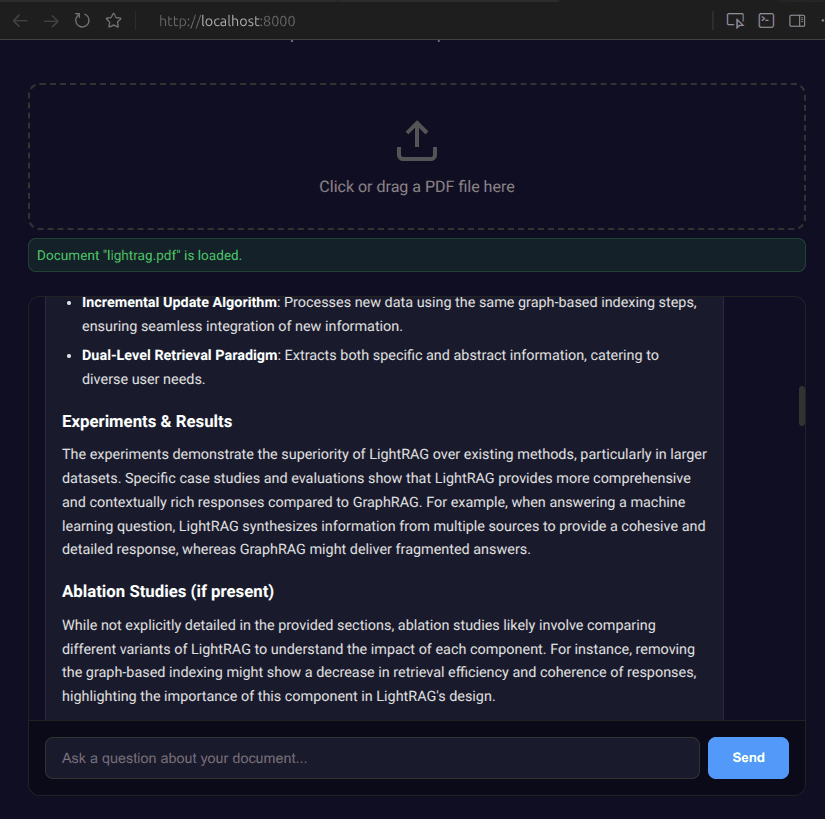
Key Components
Experiments & Results
Ablation Studies (if present)
Conclusions
after token trimming, whatever context fits within the ~8K input budget gets sent with 2048 output tokens reserved. the answer comes back as structured markdown, not a three-sentence shrug.
this is how we summarize a paper that's 5× larger than the context window without ever reading the whole thing at once. we sample the whole thing, retrieve the important parts, and let the LLM synthesize.
overall, this project was assisted by coding tool (of course, im not a programming god) also the recruitment also said to finish this task using AI-assisted programming tool. it took me 2-3 days to finish this task. i dont know whether this is the best practice to solve this task, or if this is the wrong approach. if any of you are LLM practicioners, let me know how i can do this better
time taken to write this: 40 minutes (ah)
until next time,
indira